Apache Iceberg Lakehouse
Overview
- Deploy Object Storage, Apache Spark, Iceberg catalog, and StarRocks using Docker compose
- Load New York City Green Taxi data for the month of May 2023 into the Iceberg data lake
- Configure StarRocks to access the Iceberg catalog
- Query the data with StarRocks where the data sits
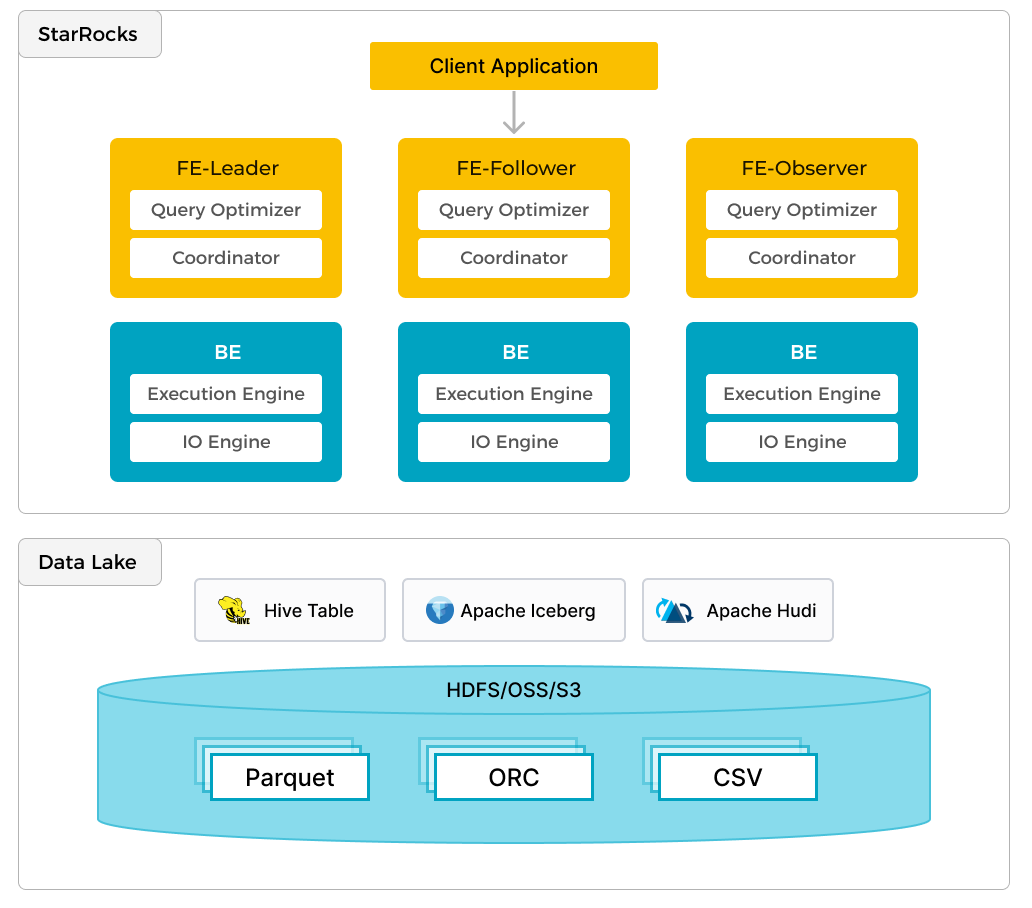
In addition to efficient analytics of local data, StarRocks can work as the compute engine to analyze data stored in data lakes such as Apache Hudi, Apache Iceberg, and Delta Lake. One of the key features of StarRocks is its external catalog, which acts as the linkage to an externally maintained metastore. This functionality provides users with the capability to query external data sources seamlessly, eliminating the need for data migration. As such, users can analyze data from different systems such as HDFS and Amazon S3, in various file formats such as Parquet, ORC, and CSV, etc.
The preceding figure shows a data lake analytics scenario where StarRocks is responsible for data computing and analysis, and the data lake is responsible for data storage, organization, and maintenance. Data lakes allow users to store data in open storage formats and use flexible schemas to produce reports on "single source of truth" for various BI, AI, ad-hoc, and reporting use cases. StarRocks fully leverages the advantages of its vectorization engine and CBO, significantly improving the performance of data lake analytics.
Prerequisites
Docker
- Docker
- 5 GB RAM assigned to Docker
- 20 GB free disk space assigned to Docker
SQL client
You can use the SQL client provided in the Docker environment, or use one on your system. Many MySQL compatible clients will work, and this guide covers the configuration of DBeaver and MySQL WorkBench.
curl
curl is used to download the datasets. Check to see if you have it installed by running curl or curl.exe at your OS prompt. If curl is not installed, get curl here.
StarRocks terminology
FE
Frontend nodes are responsible for metadata management, client connection management, query planning, and query scheduling. Each FE stores and maintains a complete copy of metadata in its memory, which guarantees indiscriminate services among the FEs.
BE
Backend (BE) nodes are responsible for both data storage and executing query plans in shared-nothing deployments. When an external catalog (like the Iceberg catalog used in this guide) is used, the BE nodes can cache the data from the external catalog to accelerate queries.
The environment
There are six containers (services) used in this guide, and all are deployed with Docker compose. The services and their responsibilities are:
| Service | Responsibilities |
|---|---|
starrocks-fe | Metadata management, client connections, query plans and scheduling |
starrocks-be | Running query plans |
rest | Providing the Iceberg catalog (metadata service) |
spark-iceberg | An Apache Spark environment to run PySpark in |
mc | MinIO configuration (MinIO command line client) |
minio | MinIO Object Storage |
Download the Docker configuration and NYC Green Taxi data
In order to provide an environment with the three necessary containers StarRocks provides a Docker compose file. Download the compose file and dataset with curl.
The Docker compose file:
mkdir iceberg
cd iceberg
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/iceberg/docker-compose.yml
And the dataset:
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/iceberg/datasets/green_tripdata_2023-05.parquet
Start the environment in Docker
Run this command, and any other docker compose commands, from the directory containing the docker-compose.yml file.
docker compose up -d
[+] Building 0.0s (0/0) docker:desktop-linux
[+] Running 6/6
✔ Container iceberg-rest Started 0.0s
✔ Container minio Started 0.0s
✔ Container starrocks-fe Started 0.0s
✔ Container mc Started 0.0s
✔ Container spark-iceberg Started 0.0s
✔ Container starrocks-be Started
Check the status of the environment
Check the progress of the services. It should take around 30 seconds for the FE and BE to become healthy.
Run docker compose ps until the FE and BE show a status of healthy. The rest of the services do not have healthcheck configurations, but you will be interacting with them and will know whether or not they are working:
If you have jq installed and prefer a shorter list from docker compose ps try:
docker compose ps --format json | jq '{Service: .Service, State: .State, Status: .Status}'
docker compose ps
SERVICE CREATED STATUS PORTS
rest 4 minutes ago Up 4 minutes 0.0.0.0:8181->8181/tcp
mc 4 minutes ago Up 4 minutes
minio 4 minutes ago Up 4 minutes 0.0.0.0:9000-9001->9000-9001/tcp
spark-iceberg 4 minutes ago Up 4 minutes 0.0.0.0:8080->8080/tcp, 0.0.0.0:8888->8888/tcp, 0.0.0.0:10000-10001->10000-10001/tcp
starrocks-be 4 minutes ago Up 4 minutes (healthy) 0.0.0.0:8040->8040/tcp
starrocks-fe 4 minutes ago Up 4 minutes (healthy) 0.0.0.0:8030->8030/tcp, 0.0.0.0:9020->9020/tcp, 0.0.0.0:9030->9030/tcp
PySpark
There are several ways to interact with Iceberg, this guide uses PySpark. If you are not familiar with PySpark there is documentation linked from the More Information section, but every command that you need to run is provided below.
Green Taxi dataset
Copy the data to the spark-iceberg container. This command will copy the dataset file to the /opt/spark/ directory in the spark-iceberg service:
docker compose \
cp green_tripdata_2023-05.parquet spark-iceberg:/opt/spark/
Launch PySpark
This command will connect to the spark-iceberg service and run the command pyspark:
docker compose exec -it spark-iceberg pyspark
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.5.0
/_/
Using Python version 3.9.18 (main, Nov 1 2023 11:04:44)
Spark context Web UI available at http://6ad5cb0e6335:4041
Spark context available as 'sc' (master = local[*], app id = local-1701967093057).
SparkSession available as 'spark'.
>>>
Read the dataset into a dataframe
A dataframe is park of Spark SQL, and provides a data structure similar to a database table or a spreadsheet.
The Green Taxi data is provided by NYC Taxi and Limousine Commission in Parquet format. Load the file from the /opt/spark directory and inspect the first few records by SELECTing the first few columns of the first three rows of data. These commands should be run in the pyspark session. The commands:
- Read the dataset file from disk into a dataframe named
df - Display the schema of the Parquet file
df = spark.read.parquet("/opt/spark/green_tripdata_2023-05.parquet")
df.printSchema()
root
|-- VendorID: integer (nullable = true)
|-- lpep_pickup_datetime: timestamp_ntz (nullable = true)
|-- lpep_dropoff_datetime: timestamp_ntz (nullable = true)
|-- store_and_fwd_flag: string (nullable = true)
|-- RatecodeID: long (nullable = true)
|-- PULocationID: integer (nullable = true)
|-- DOLocationID: integer (nullable = true)
|-- passenger_count: long (nullable = true)
|-- trip_distance: double (nullable = true)
|-- fare_amount: double (nullable = true)
|-- extra: double (nullable = true)
|-- mta_tax: double (nullable = true)
|-- tip_amount: double (nullable = true)
|-- tolls_amount: double (nullable = true)
|-- ehail_fee: double (nullable = true)
|-- improvement_surcharge: double (nullable = true)
|-- total_amount: double (nullable = true)
|-- payment_type: long (nullable = true)
|-- trip_type: long (nullable = true)
|-- congestion_surcharge: double (nullable = true)
>>>
Examine the first few (seven) columns of the first few (three) rows of data:
df.select(df.columns[:7]).show(3)
+--------+--------------------+---------------------+------------------+----------+------------+------------+
|VendorID|lpep_pickup_datetime|lpep_dropoff_datetime|store_and_fwd_flag|RatecodeID|PULocationID|DOLocationID|
+--------+--------------------+---------------------+------------------+----------+------------+------------+
| 2| 2023-05-01 00:52:10| 2023-05-01 01:05:26| N| 1| 244| 213|
| 2| 2023-05-01 00:29:49| 2023-05-01 00:50:11| N| 1| 33| 100|
| 2| 2023-05-01 00:25:19| 2023-05-01 00:32:12| N| 1| 244| 244|
+--------+--------------------+---------------------+------------------+----------+------------+------------+
only showing top 3 rows
Write to a table
The table created in this step will be in the catalog that will be made available in StarRocks in the next step.
- Catalog:
demo - Database:
nyc - Table:
greentaxis
df.writeTo("demo.nyc.greentaxis").create()
Configure StarRocks to access the Iceberg Catalog
You can exit from PySpark now, or you can open a new terminal to run the SQL commands. If you do open a new terminal change your directory into the quickstart directory that contains the docker-compose.yml file before continuing.
Connect to StarRocks with a SQL client
SQL Clients
These three clients are tested with this tutorial, you only need one:
- mysql CLI: You can run this from the Docker environment or your machine.
- DBeaver is available as a community version and a Pro version.
- MySQL Workbench
Configuring the client
- mysql CLI
- DBeaver
- MySQL Workbench
The easiest way to use the mysql CLI is to run it from the StarRocks container starrocks-fe:
docker compose exec starrocks-fe \
mysql -P 9030 -h 127.0.0.1 -u root --prompt="StarRocks > "
All docker compose commands must be run from the directory containing the docker-compose.yml file.
If you would like to install the mysql CLI expand mysql client install below:
mysql client install
- macOS: If you use Homebrew and do not need MySQL Server run
brew install mysqlto install the CLI. - Linux: Check your repository system for the
mysqlclient. For example,yum install mariadb. - Microsoft Windows: Install the MySQL Community Server and run the provided client, or run
mysqlfrom WSL.
- Install DBeaver, and add a connection:

- Configure the port, IP, and username. Test the connection, and click Finish if the test succeeds:
- Install the MySQL Workbench, and add a connection.
- Configure the port, IP, and username and then test the connection:
- You will see warnings from the Workbench as it is checking for a specific MySQL version. You can ignore the warnings and when prompted, you can configure Workbench to stop displaying the warnings:
You can now exit the PySpark session and connect to StarRocks.
Run this command from the directory containing the docker-compose.yml file.
If you are using a client other than the mysql CLI, open that now.
docker compose exec starrocks-fe \
mysql -P 9030 -h 127.0.0.1 -u root --prompt="StarRocks > "
StarRocks >
Create an external catalog
The external catalog is the configuration that allows StarRocks to operate on the Iceberg data as if it was in StarRocks databases and tables. The individual configuration properties will be detailed after the command.
CREATE EXTERNAL CATALOG 'iceberg'
PROPERTIES
(
"type"="iceberg",
"iceberg.catalog.type"="rest",
"iceberg.catalog.uri"="http://iceberg-rest:8181",
"iceberg.catalog.warehouse"="warehouse",
"aws.s3.access_key"="admin",
"aws.s3.secret_key"="password",
"aws.s3.endpoint"="http://minio:9000",
"aws.s3.enable_path_style_access"="true",
"client.factory"="com.starrocks.connector.iceberg.IcebergAwsClientFactory"
);
PROPERTIES
| Property | Description |
|---|---|
type | In this example the type is iceberg. Other options include Hive, Hudi, Delta Lake, and JDBC. |
iceberg.catalog.type | In this example rest is used. Tabular provides the Docker image used and Tabular uses REST. |
iceberg.catalog.uri | The REST server endpoint. |
iceberg.catalog.warehouse | The identifier of the Iceberg catalog. In this case the warehouse name specified in the compose file is warehouse. |
aws.s3.access_key | The MinIO key. In this case the key and password are set in the compose file to admin |
aws.s3.secret_key | and password. |
aws.s3.endpoint | The MinIO endpoint. |
aws.s3.enable_path_style_access | When using MinIO for Object Storage this is required. MinIO expects this format http://host:port/<bucket_name>/<key_name> |
client.factory | By setting this property to use iceberg.IcebergAwsClientFactory the aws.s3.access_key and aws.s3.secret_key parameters are used for authentication. |
SHOW CATALOGS;
+-----------------+----------+------------------------------------------------------------------+
| Catalog | Type | Comment |
+-----------------+----------+------------------------------------------------------------------+
| default_catalog | Internal | An internal catalog contains this cluster's self-managed tables. |
| iceberg | Iceberg | NULL |
+-----------------+----------+------------------------------------------------------------------+
2 rows in set (0.03 sec)
SET CATALOG iceberg;
SHOW DATABASES;
The database that you see was created in your PySpark
session. When you added the CATALOG iceberg, the
database nyc became visible in StarRocks.
+----------+
| Database |
+----------+
| nyc |
+----------+
1 row in set (0.07 sec)
USE nyc;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
SHOW TABLES;
+---------------+
| Tables_in_nyc |
+---------------+
| greentaxis |
+---------------+
1 rows in set (0.05 sec)
DESCRIBE greentaxis;
Compare the schema that StarRocks uses with the output of df.printSchema() from the earlier PySpark session. The Spark timestamp_ntz data types are represented as StarRocks DATETIME etc.
+-----------------------+------------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------------+------------------+------+-------+---------+-------+
| VendorID | INT | Yes | false | NULL | |
| lpep_pickup_datetime | DATETIME | Yes | false | NULL | |
| lpep_dropoff_datetime | DATETIME | Yes | false | NULL | |
| store_and_fwd_flag | VARCHAR(1048576) | Yes | false | NULL | |
| RatecodeID | BIGINT | Yes | false | NULL | |
| PULocationID | INT | Yes | false | NULL | |
| DOLocationID | INT | Yes | false | NULL | |
| passenger_count | BIGINT | Yes | false | NULL | |
| trip_distance | DOUBLE | Yes | false | NULL | |
| fare_amount | DOUBLE | Yes | false | NULL | |
| extra | DOUBLE | Yes | false | NULL | |
| mta_tax | DOUBLE | Yes | false | NULL | |
| tip_amount | DOUBLE | Yes | false | NULL | |
| tolls_amount | DOUBLE | Yes | false | NULL | |
| ehail_fee | DOUBLE | Yes | false | NULL | |
| improvement_surcharge | DOUBLE | Yes | false | NULL | |
| total_amount | DOUBLE | Yes | false | NULL | |
| payment_type | BIGINT | Yes | false | NULL | |
| trip_type | BIGINT | Yes | false | NULL | |
| congestion_surcharge | DOUBLE | Yes | false | NULL | |
+-----------------------+------------------+------+-------+---------+-------+
20 rows in set (0.04 sec)
Some of the SQL queries in the StarRocks documentation end with \G instead
of a semicolon. The \G causes the mysql CLI to render the query results vertically.
Many SQL clients do not interpret vertical formatting output, so you should replace \G with ; if you are not using the mysql CLI.
Query with StarRocks
Verify pickup datetime format
SELECT lpep_pickup_datetime FROM greentaxis LIMIT 10;
+----------------------+
| lpep_pickup_datetime |
+----------------------+
| 2023-05-01 00:52:10 |
| 2023-05-01 00:29:49 |
| 2023-05-01 00:25:19 |
| 2023-05-01 00:07:06 |
| 2023-05-01 00:43:31 |
| 2023-05-01 00:51:54 |
| 2023-05-01 00:27:46 |
| 2023-05-01 00:27:14 |
| 2023-05-01 00:24:14 |
| 2023-05-01 00:46:55 |
+----------------------+
10 rows in set (0.07 sec)
Find the busy hours
This query aggregates the trips on the hour of the day and shows that the busiest hour of the day is 18:00.
SELECT COUNT(*) AS trips,
hour(lpep_pickup_datetime) AS hour_of_day
FROM greentaxis
GROUP BY hour_of_day
ORDER BY trips DESC;
+-------+-------------+
| trips | hour_of_day |
+-------+-------------+
| 5381 | 18 |
| 5253 | 17 |
| 5091 | 16 |
| 4736 | 15 |
| 4393 | 14 |
| 4275 | 19 |
| 3893 | 12 |
| 3816 | 11 |
| 3685 | 13 |
| 3616 | 9 |
| 3530 | 10 |
| 3361 | 20 |
| 3315 | 8 |
| 2917 | 21 |
| 2680 | 7 |
| 2322 | 22 |
| 1735 | 23 |
| 1202 | 6 |
| 1189 | 0 |
| 806 | 1 |
| 606 | 2 |
| 513 | 3 |
| 451 | 5 |
| 408 | 4 |
+-------+-------------+
24 rows in set (0.08 sec)
Summary
This tutorial exposed you to the use of a StarRocks external catalog to show you that you can query your data where it sits using the Iceberg REST catalog. Many other integrations are available using Hive, Hudi, Delta Lake, and JDBC catalogs.
In this tutorial you:
- Deployed StarRocks and an Iceberg/PySpark/MinIO environment in Docker
- Configured a StarRocks external catalog to provide access to the Iceberg catalog
- Loaded taxi data provided by New York City into the Iceberg data lake
- Queried the data with SQL in StarRocks without copying the data from the data lake
More information
Apache Iceberg documentation and Quickstart (includes PySpark)
The Green Taxi Trip Records dataset is provided by New York City subject to these terms of use and privacy policy.