Data Lakehouse
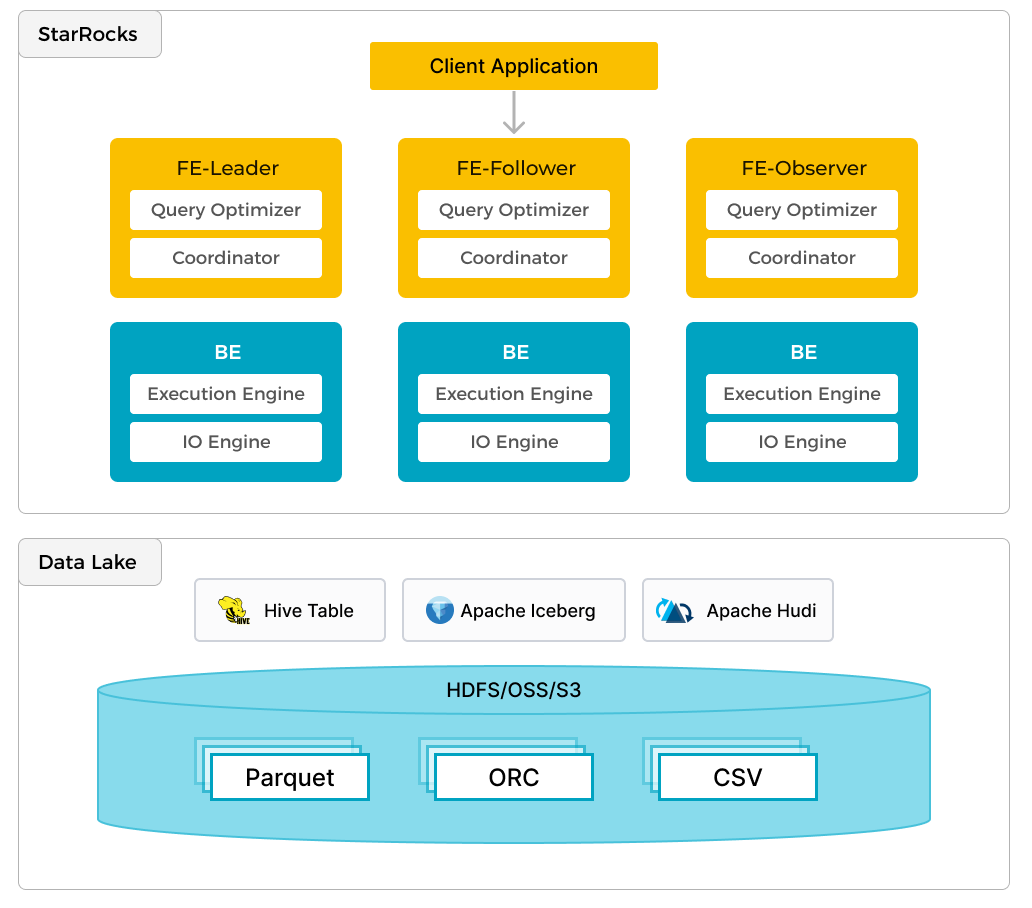
In addition to efficient analytics of local data, StarRocks can work as the compute engine to analyze data stored in data lakes such as Apache Hudi, Apache Iceberg, and Delta Lake. One of the key features of StarRocks is its external catalog, which acts as the linkage to an externally maintained metastore. This functionality provides users with the capability to query external data sources seamlessly, eliminating the need for data migration. As such, users can analyze data from different systems such as HDFS and Amazon S3, in various file formats such as Parquet, ORC, and CSV, etc.
The preceding figure shows a data lake analytics scenario where StarRocks is responsible for data computing and analysis, and the data lake is responsible for data storage, organization, and maintenance. Data lakes allow users to store data in open storage formats and use flexible schemas to produce reports on "single source of truth" for various BI, AI, ad-hoc, and reporting use cases. StarRocks fully leverages the advantages of its vectorization engine and CBO, significantly improving the performance of data lake analytics.
Key ideas
- Open Data Formats: Supports a variety of data types, including JSON, Parquet, and Avro, facilitating the storage and processing of both structured and unstructured data.
- Metadata Management: Implements a shared metadata layer, often utilizing formats like the Iceberg table format, to organize and govern data efficiently.
- Diverse Query Engines: Incorporates multiple engines, like enhanced versions of Presto and Spark, to cater to various analytics and AI use cases.
- Governance and Security: Features robust built-in mechanisms for data security, privacy, and compliance, ensuring data integrity and trustworthiness.
Advantages of Data Lakehouse architecture
- Flexibility and Scalability: Seamlessly manages diverse data types and scales with the organization’s needs.
- Cost-Effectiveness: Offers an economical alternative for data storage and processing, compared to traditional methods.
- Enhanced Data Governance: Improves data control, management, and integrity, ensuring reliable and secure data handling.
- AI and Analytics Readiness: Perfectly suited for complex analytical tasks, including machine learning and AI-driven data processing.
StarRocks approach
The key things to consider are:
- Standardizing the integration with catalog, or metadata services
- Elastic scalability of compute nodes
- Flexible caching mechanisms
Catalogs
StarRocks has two types of catalogs, internal and external. The internal catalog contains metadata for data stored within StarRocks databases. External catalogs are used to work with data stored externally, including the data managed by Hive, Iceberg, Delta Lake, and Hudi. There are many other external systems, links are in the More Information section at the bottom of the page.
Compute node (CN) scaling
Separation of storage and compute reduces the complexity of scaling. Since the StarRocks compute nodes are only storing local cache, nodes can be added or removed based on load.
Data cache
Cache on the compute nodes is optional. If your compute nodes are spinning up and down quickly based on quickly changing load patterns or your queries are often only on the most recent data it might not make sense to cache data.
Learn by doing
Try out a Docker based lakehouse. This data lakehouse tutorial creates a data lake built with Iceberg and MinIO and connects StarRocks containers as the query engine. Load the provided dataset, or add your own.
🗃️ Catalog
12 items
📄️ External table
- From v3.0 onwards, we recommend that you use catalogs to query data from Hive, Iceberg, and Hudi. See Hive catalog, Iceberg catalog, and Hudi catalog.
📄️ File external table
File external table is a special type of external table. It allows you to directly query Parquet and ORC data files in external storage systems without loading data into StarRocks. In addition, file external tables do not rely on a metastore. In the current version, StarRocks supports the following external storage systems: HDFS, Amazon S3, and other S3-compatible storage systems.
📄️ Data Cache
This topic describes the working principles of Data Cache and how to enable Data Cache to improve query performance on external data.
📄️ Data lake FAQ
This topic describes some commonly asked questions (FAQ) about data lake and provides solutions to these issues. Some metrics mentioned in this topic can be obtained only from the profiles of the SQL queries. To obtain the profiles of SQL queries, you must specify set enable_profile=true.